Kubernetes can support GPUs to speed parallel processing, and auto-scaling in environments that support it. This feature can be used for Machine Learning and Data Science applications. Kublr can automatically detects GPUs on AWS and Azure instances and configure the environment to use GPUs with Kubernetes.
This document explains:
On AWS Kublr supports GPUs on Ubuntu 20.04 and RedHat 7 (on RedHat 7 docker-ce is required) for number of GPU instances, for example:
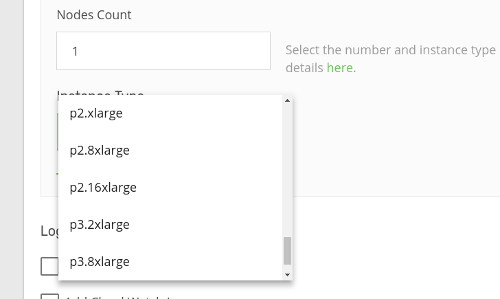
p2.xlarge;
p2.8xlarge;
p2.16xlarge;
p3.2xlarge;
p3.8xlarge;
p3.16xlarge.
Note See full list of AWS GPU instances and their technical descriptions in AWS documentation Amazon EC2 Instance Types > “Accelerated Computing”.
On Azure Kublr supports GPUs on Ubuntu 20.04 for the number of GPU instances, for example::
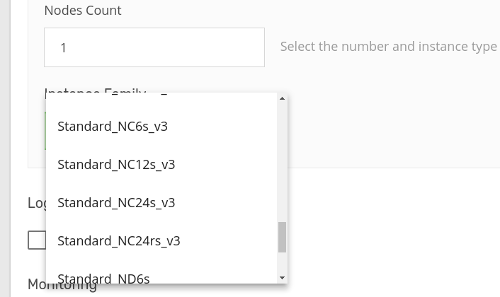
Standard_NC6s_v2;
Standard_NC12s_v2;
Standard_NC24s_v2;
Standard_NC24rs_v2;
Standard_NC6s_v3;
Standard_NC12s_v3;
Standard_NC24s_v3;
Standard_NC24rs_v3;
Standard_ND6s;
Standard_ND12s;
Standard_ND24s;
Standard_ND24rs.
Note See full list of Azure GPU instances and their technical descriptions in Azure documentation GPU optimized virtual machines > “Overview” and related sections.
Kublr supports GPU for the following NVIDIA devices:
Here is the example of Kublr configuration related to the installation of the NVIDIA devices:
spec:
nodes:
- name: ml
kublrAgentConfig:
kublr:
features:
nvidia_devices:
enable: 'auto' # 'auto' is the default value, it does not have to be
#specified explicitly, and it is placed here for
# demonstration purpose only
This defines whether to enable NVidia devices support. Possible values are:
true means that nvidia drivers and docker runtime are installed during setup and enabled in runtimefalse means that nvidia drivers and docker runtime are NOT installed during setup and NOT enabled in runtimeauto (default) means that Kublr will do its best to decide whether to install/enable nvidia drivers and docker runtime.
Currently the decision to install drivers is made based on availability of nvidia devices in ‘lspci’ output,
and decision to enable them is based on availability of nvidia devices in ‘lspci’ output and installed drivers and docker runtime files.Nvidia GPU support feature by default relies on the latest nvidia driver version included in nvidia, so if the latest driver version published by Nvidia does not support the GPU hardware present in the system, enabling GPU support will require specifying exact driver version in the Kublr cluster specification.
Notably, this is the case for most AWS GPU accelerated instance types such as p2.*, p3.*, g5.*, g4dn.*, g3(s).*.
GPU hardware provided by AWS on these instance types (Nvidia K80, Nidia Tesla V100, Nvidia A10G Tensor Core, Nvidia T4 Tensor Core,
and Nvidia Tesla M60 correspondingly) is not supported by the default latest version of Nvidia GPU drivers provided by Nvidia.
As a result an earlier version driver must be specified explicitely in the Kublr cluster spec for a corresponding worker node
group in kublrAgentConfig section property kublr.features.nvidia_devices.driver.
Driver nvidia-driver-470-server is tested to support GPU devices provided in all the above instance types on Ubuntu 18.04 and
Ubuntu 20.04 images.
When RHEL or Centos images are used, the driver nvidia-driver-branch-470 is known to work well.
Additionally for RHEL backed instances it is important to use Docker CE instead of default docker provided with the OS. This is due to the fact that RHEL provided version of Docker is based on quite old Docker CE version and does not work well with Nvidia container runtime that is required for Nvidia GPU integration.
Ubuntu 20.04 Kublr configuration example for NVIDIA drivers:
spec:
...
nodes:
- autoscaling: false
kublrVariant: aws-ubuntu-20.04
...
name: group1
# this "kublrAgentConfig" section allows customizing Kublr agent running on this
# worker node group; in this case setting a specific version of nvidia driver.
kublrAgentConfig:
kublr:
features:
nvidia_devices:
driver:
- nvidia-driver-470-server
enable: 'true'
RedHat 7 Kublr configuration example for NVIDIA drivers and docker-ce:
spec:
...
nodes:
- autoscaling: false
kublrVariant: aws-redhat-8
...
name: group1
# this "kublrAgentConfig" section allows customizing Kublr agent running on this
# worker node group; in this case setting a specific version of nvidia driver and
# Docker CE preference.
kublrAgentConfig:
kublr:
features:
nvidia_devices:
driver:
- nvidia-driver-branch-470
enable: auto
setup:
docker:
edition_fallback_order: 'ce,os'
Kublr does not support GPUs on Google Cloud Platform (GCP).
For your own infrastructure you will be able to use GPUs if they are the installed and configured part of your machine.
On AWS:
 On Azure:
On Azure:
Click ‘Create Cluster’ and wait until the cluster is created.
# lspci -m -nn
....
00:1e.0 "3D controller [0302]""NVIDIA Corporation [10de]""GK210GL [Tesla K80] [102d]"-ra1 "NVIDIA Corporation [10de]""Device [106c]"
....
#
#
# nvidia-smi
Mon Jun 18 10:15:50 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.26 Driver Version: 396.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A50C P8 27W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
#
# nvidia-smi -L
GPU 0: Tesla K80 (UUID: GPU-860ba7bf-e331-54b4-6e2c-322fb389597b)
# docker run --rm nvidia/cuda nvidia-smi
Mon Jun 18 10:15:50 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.26 Driver Version: 396.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A50C P8 27W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Prerequisites:
Copy KubeConfig file from cluster’s Overview page and move it to ~/.kube/ directory
$ cp ~/Downloads/config.yaml ~/.kube/config
Check that kubectl is working and using right config file:
$ kubectl config view
$ kubectl cluster-info
Change directory to ../demo7-gpu and install helm chart
$ helm install demo ./
NAME: demo
LAST DEPLOYED: Fri Jun 24 07:58:32 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app=demo-gpu,release=demo" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl port-forward $POD_NAME 8080:80
Run command for port forwarding (pod_name in the previous console output).
$ kubectl port-forward <POD_NAME> 8000:8000 --address 0.0.0.0
Forwarding from 0.0.0.0:8000 -> 8000
Handling connection for 8000
Get video streem: open this link in browser http://localhost:8000/

Note that it may take couple minutes before video stream is available within the browser. Once the video stream is up and demo chart is working, you may verify NVIDIA GPU acceleration using command:
(see below GPU % utilization and process id)
# nvidia-smi
Fri Jun 24 09:11:39 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.129.06 Driver Version: 470.129.06 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A 62C P0 142W / 149W | 1364MiB / 11441MiB | 82% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 161012 C python 1361MiB |
+-----------------------------------------------------------------------------+
root@ip-172-16-61-0:/#
root@ip-172-16-61-0:/# nvidia-smi -q -g 0 -d UTILIZATION -l
==============NVSMI LOG==============
Timestamp : Fri Jun 24 09:15:18 2022
Driver Version : 470.129.06
CUDA Version : 11.4
Attached GPUs : 1
GPU 00000000:00:1E.0
Utilization
Gpu : 83 %
Memory : 38 %
Encoder : 0 %
Decoder : 0 %
GPU Utilization Samples
Duration : 16.58 sec
Number of Samples : 99
Max : 85 %
Min : 73 %
Avg : 80 %
Memory Utilization Samples
Duration : 16.58 sec
Number of Samples : 99
Max : 39 %
Min : 34 %
Avg : 37 %
Open file ../demo7-gpu/dockerGPUHelm/templates/deployment.yaml
Change the value of parameter VIDEO_LINK. Note: you can change value of VIDEO_OUTPUT_COMPRESSION for the desired video quality level.
Upgrade the helm chart. Note: You should wait approximately a minute until the previous Pod is terminated.
$ helm upgrade demo ./
Release "demo" has been upgraded. Happy Helming!
LAST DEPLOYED: Fri Jun 24 07:58:32 2022
NAMESPACE: default
STATUS: DEPLOYED
$ kubectl get pods --all-namespaces |grep demo
Run command for port forwarding.
Open link http://localhost:8000/ to get video stream.

In the process of installing the cluster, Kublr checks for the presence of GPU devices and, if detected, does the following:
Install NVIDIA drivers.
Install nvidia runtime for docker.
Configure docker to use nvidia runtime:
a. For Ubuntu 20.04 use the following example to customize specification:
kublrAgentConfig:
kublr:
features:
nvidia_devices:
driver:
- nvidia-driver-470-server
enable: 'true'
b. For RedHat 7 use the following example to customize specification:
kublrAgentConfig:
kublr:
features:
nvidia_devices:
driver:
- nvidia-driver-branch-470
enable: auto
setup:
docker:
edition_fallback_order: 'ce,os'
